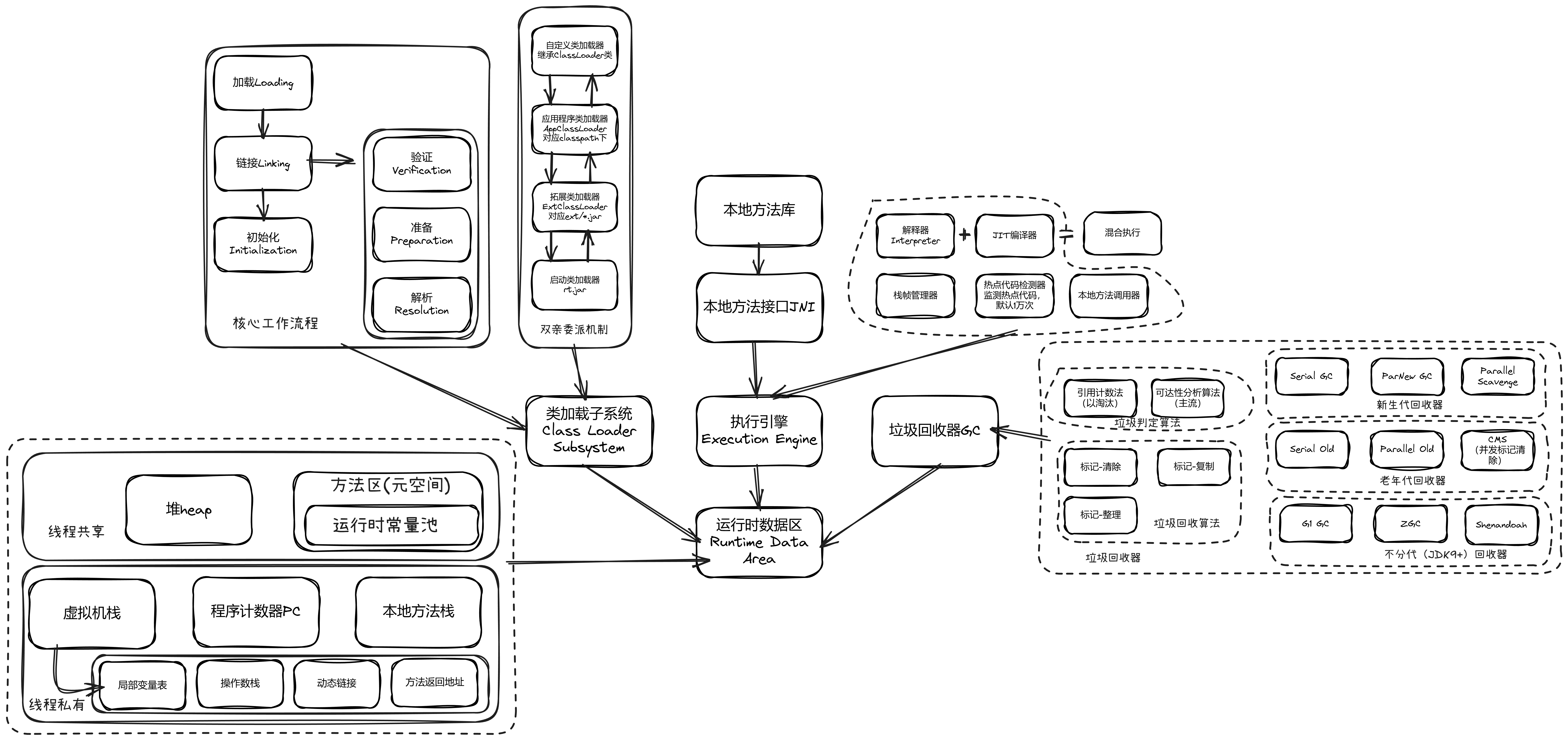
JVM(Java Virtual Machine)是 Java“一次编写,到处运行” 的核心,其底层本质是将 Java 字节码(.class 文件)转换为操作系统能识别的机器码,并提供内存管理、线程调度等核心能力。
JVM 的底层架构可以分为 5 个核心模块,它们协同工作完成 Java 程序的执行,整体架构如下:
底层作用:将磁盘上的.class文件(字节码)加载到 JVM 的内存中,并完成验证、准备、解析,最终生成可以被执行的 Class 对象。
这是 JVM 底层最核心的内存管理区域,所有运行时的数据都存在这里,它被划分为 5 个区域,每个区域有明确的底层职责:
| 区域名称 | 底层作用 | 线程是否私有 | 核心特点 |
|---|---|---|---|
| 程序计数器 | 记录当前线程执行的字节码行号,线程切换时恢复执行位置 | 是 | 唯一不会 OOM 的区域 |
| 虚拟机栈 | 存储每个方法的栈帧(局部变量、方法参数、返回地址等),方法调用 = 入栈,执行完 = 出栈 | 是 | 栈深度过大会抛StackOverflowError |
| 本地方法栈 | 作用和虚拟机栈一致,但服务于本地方法(如native修饰的方法) | 是 | 同样会抛 StackOverflowError |
| 堆(Heap) | 存储所有对象实例和数组,是 GC(垃圾回收)的核心区域 | 否(共享) | 内存不足会抛OutOfMemoryError(OOM) |
| 方法区(元空间) | 存储类的元数据(类名、方法名、字段、常量池等),JDK8 后替换为 “元空间”(直接使用本地内存) | 否(共享) | 元数据过多会抛 OOM |
底层作用:将加载到内存的字节码转换为 CPU 能执行的机器码,是 JVM “执行代码” 的核心。它有两种执行方式:
底层逻辑:JVM 默认是 “解释器 + JIT” 混合模式 —— 程序启动时用解释器快速执行,运行中 JIT 编译热点代码,兼顾启动速度和执行效率。
底层作用:JVM 是用 C/C++ 实现的,当 Java 代码调用native方法(如System.currentTimeMillis())时,JNI 作为 “桥梁”,让 Java 代码能调用底层操作系统的 C/C++ 函数(本地方法库),实现和硬件 / 操作系统的交互。
底层作用:自动回收堆中不再被引用的对象内存(避免内存泄漏),是 JVM “内存管家”。
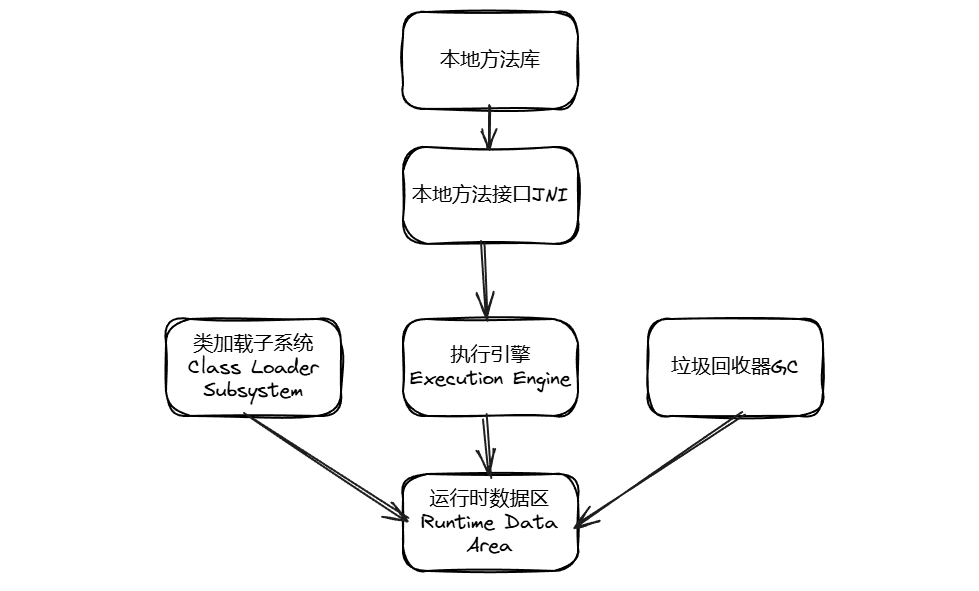
类加载子系统的工作分为 3 个核心阶段:加载(Loading)→ 链接(Linking)→ 初始化(Initialization),这三个阶段按顺序执行(解析阶段可能在初始化后执行,为了支持动态绑定)。
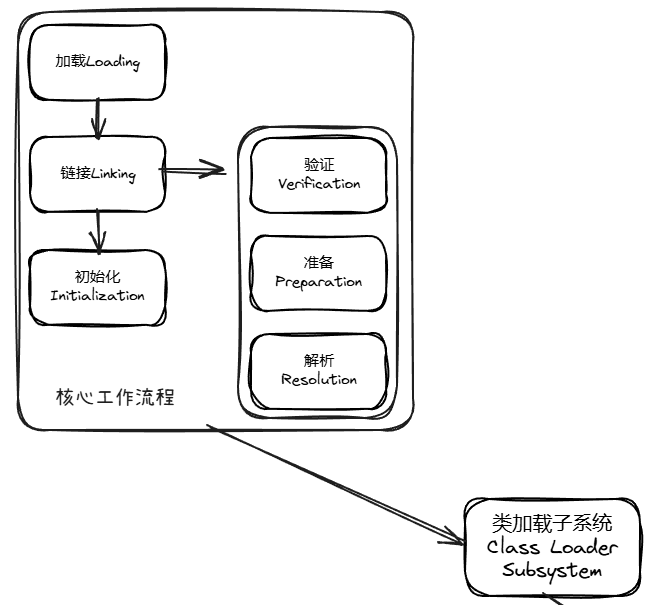
类加载的的第一步,核心是“找到.class文件并加载到内存”。
链接是类加载的核心校验和准备阶段,分为 3 个子步骤,确保加载的类符合 JVM 规范且能正常运行:
1、验证(Verification)——“安检”
核心是检查字节码是否合法、安全,避免恶意或错误的字节码导致JVM崩溃,主要做4类校验:
文件格式校验:检查.class文件的魔数(Magic Number,固定是0xCAFEBABE,如下图)、版本号(如JDK8编译的类不能在JDK7的JVM中运行)是否合法。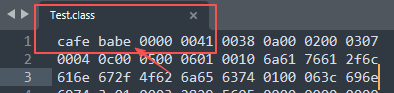
元数据校验:检查类的继承关系、字段 / 方法的语法是否符合 Java 规范(比如不能继承final类,不能重写final方法);
字节码校验:检查字节码指令的逻辑是否合法(比如不能跳转到不存在的行号,不能操作非法类型的变量);
符号引用校验:检查类引用的其他类 / 方法是否存在(比如User类引用了Order类,要确认Order类能被找到)。

关键作用:如果验证失败,会抛出VerifyError,比如用修改工具篡改.class文件的魔数,JVM 在验证阶段就会报错。
2、准备(Preparation)——“分配内存,设默认值”
核心是为类的静态变量(类变量) 分配内存(存储在方法区),并设置默认初始值(不是代码中赋值的实际值)。
| 数据类型 | 默认初始值 | 代码中赋值的实际值 |
|---|---|---|
| int | 0 | 比如static int a = 10;中的 10 |
| boolean | false | 比如static boolean flag = true;中的 true |
| 对象引用 | null | 比如static User u = new User();中的 new User () |
注意:
static final)是特例:准备阶段会直接赋值为代码中的常量值(比如static final int b = 20;,准备阶段 b 就会被赋值为 20,而非 0)。 3、解析(Resolution)——“符号引用→直接引用”
核心是将常量池中的符号引用(比如代码中写的User u = new User();里的User)转换为直接引用(内存地址,比如方法区中User.class对象的内存地址)。
关键时机:解析阶段不一定在准备后立即执行,JVM 支持 “懒解析”—— 只有在实际使用该引用时才解析(比如调用User类的方法时,才解析User的符号引用),目的是提升类加载效率。
这是类加载的最后一步,核心是执行类的静态代码块(static {}),并为静态变量赋代码中定义的实际值。
执行顺序:
public class Parent {
static int parentAge = 50;
static {
System.out.println("Parent静态代码块执行");
}
}
public class Child extends Parent {
static int childAge = 20;
static {
System.out.println("Child静态代码块执行");
}
}
// 测试代码
public class Test {
public static void main(String[] args) {
System.out.println(Child.childAge);
}
}
执行结果:
Parent静态代码块执行
Child静态代码块执行
20
过程逻辑:访问Child.childAge触发Child类的初始化,JVM 先初始化父类Parent(执行parentAge=50+ 父类静态代码块),再初始化Child(执行childAge=20+ 子类静态代码块)。
触发初始化的场景(主动使用):
只有以下 6 种 “主动使用” 场景会触发类的初始化,其他情况(比如仅引用静态常量)不会触发:
new Child());Class.forName("com.example.Child"));main方法的类)会被优先初始化。类加载子系统的核心是 “类加载器”,它负责执行上述的加载阶段,JVM 内置了 3 类加载器,且遵循 “双亲委派模型”,这是类加载的核心规则。
JVM 的类加载器分为 4 类(3 个内置 + 1 个自定义),各自负责加载不同范围的类:
| 类加载器类型 | 核心作用 | 实现方式 | 加载路径示例 |
|---|---|---|---|
| 启动类加载器(Bootstrap) | 加载 JVM 核心类(java.lang.*、java.util.*等) | C/C++ 实现(无 Java 对象) | JDK 安装目录 /jre/lib/rt.jar |
| 扩展类加载器(Extension) | 加载 JVM 扩展类 | Java 实现(ExtClassLoader) | JDK 安装目录 /jre/lib/ext/*.jar |
| 应用程序类加载器(Application) | 加载应用程序的类(classpath 下的类) | Java 实现(AppClassLoader) | 项目 target/classes、Maven 依赖的 jar 包 |
| 自定义类加载器 | 加载自定义路径的类(比如加载磁盘外的类) | 继承ClassLoader实现 | 比如加载网络上的.class 文件、加密的.class 文件 |
这是类加载器的核心工作规则,目的是保证核心类的唯一性和安全性(比如避免自定义的java.lang.String覆盖 JDK 的核心String类)。
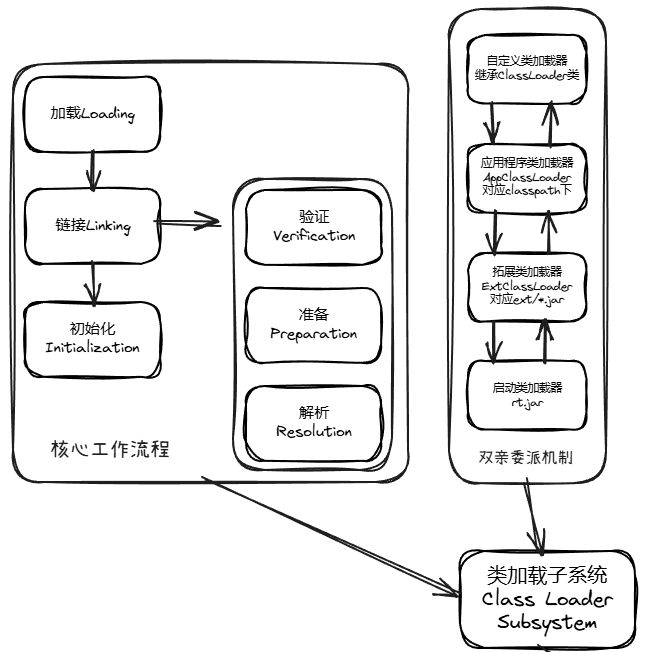
1.当一个类加载器收到加载请求时,首先委托给父加载器加载,而非自己直接加载;
2.父加载器收到请求后,继续委托给它的父加载器,直到启动类加载器;
3.启动类加载器检查是否能加载该类:能加载则直接加载,不能则向下返回给扩展类加载器;
4.扩展类加载器检查:能加载则加载,不能则向下返回给应用程序类加载器;
5.应用程序类加载器检查:能加载则加载,不能则返回给自定义类加载器;
6.自定义类加载器仍无法加载,则抛出ClassNotFoundException。
核心作用:
java.lang.String)替换 JDK 的核心类,因为启动类加载器会优先加载rt.jar中的String类,自定义的String类永远不会被加载;Class对象。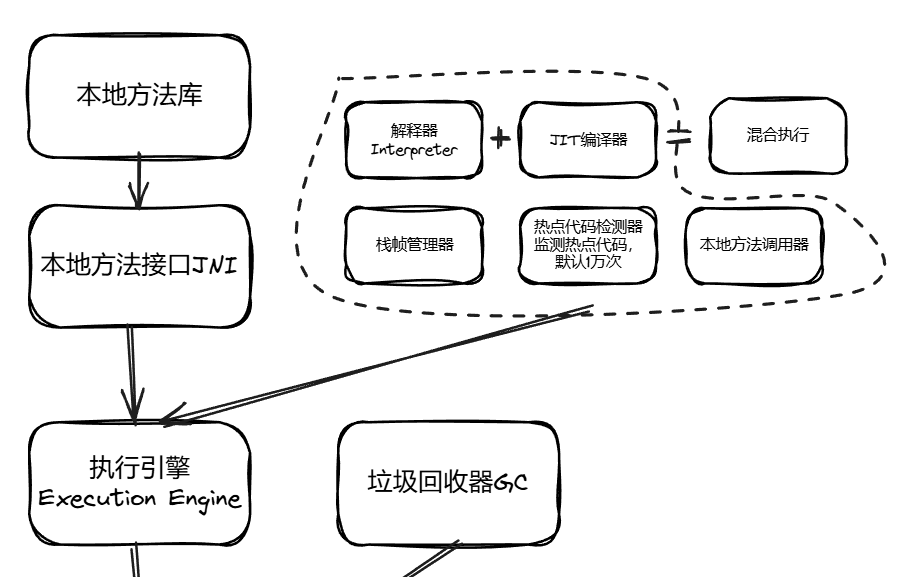
执行引擎是 JVM 的核心执行组件,也是连接 “字节码” 和 “硬件 CPU” 的桥梁,其核心作用是:将类加载子系统加载到方法区的字节码指令,转换为 CPU 能识别的机器码并执行,同时协调运行时数据区(栈帧、堆、程序计数器)完成方法调用、变量操作等逻辑。
| 组件名称 | 核心职责 |
|---|---|
| 解释器(interpreter) | 逐行将字节码指令解释为机器码并执行,是执行引擎的“基础执行器” |
| JIT编译器 | 识别“热点代码”,一次性将其编译为优化后的机器码并缓存,后续直接执行缓存 |
| 热点代码检测器(Profiler) | 实时监控字节码的执行频率,判断哪些代码是“热点代码”,触发JIT编译 |
| 栈帧管理器 | 处理方法调用的栈帧入栈/出栈,管理局部变量表、操作数栈等栈帧内容 |
| 本地方法调用器 | 调用JNI接口,衔接本地方法库,执行native方法 |
其中,解释器和JIT编译器是执行引擎的核心,JVM默认采用“解释器+JIT”的混合执行模式,兼顾程序启动速度和运行效率。
JVM支持解释执行、编译执行、混合执行三种方式,其中混合执行是默认且最优的方式。
工作原理
解释器以逐行解释、逐行执行的方式处理字节码:每次读取一条字节码指令,将其转换为对应平台的机器码,交给CPU执行,执行完再读取下一条,全程无缓存
JVM内置的解释器是模板解释器,为每一条字节码指令预先编写好对应的机器码模板,解释时直接复用模板,提升解释效率
优缺点
工作原理
由JIT编译器将整段字节码一次性编译为优化后的机器码,并存入内存缓存;后续执行该段代码时,直接调用缓存中的机器码,无需再次解释/编译。
核心前提:识别“热点代码”
JIT编译器不会对所有代码都编译,只会编译热点代码(即频繁执行的代码),热点代码的判断由热点检测器完成,判断依据有两种:
-xx:CompileThreshold调整);JIT编译器的分级
HotSpot VM 提供了C1 编译器(客户端编译器) 和C2 编译器(服务端编译器),JDK8 及以后默认开启分层编译,结合两者的优势:
优缺点
工作原理
结合解释执行和编译执行的优势:
1.程序启动阶段:用解释器逐行执行字节码,快速启动程序,避免编译等待;
2.程序运行阶段:热点检测器实时监控,将频繁执行的 “热点代码” 交给 JIT 编译器编译为机器码并缓存;
3.后续执行热点代码时,直接调用 JIT 缓存的机器码;执行非热点代码时,仍用解释器逐行执行。
核心优势
这是 JVM 的默认执行模式(可通过-Xint强制解释执行,-Xcomp强制编译执行),完美解决了 “启动速度” 和 “执行效率” 的矛盾,也是 Java 程序既能快速启动,又能在长期运行中保持高性能的关键。
public class ExecutionEngineTest {
public static void main(String[] args) {
int result = add(1, 2); // 调用add方法
System.out.println(result);
}
public static int add(int a, int b) {
return a + b; // 核心字节码:iadd
}
}
底层执行步骤:
字节码准备:类加载子系统将ExecutionEngineTest.class加载到方法区,生成Class对象,其中add方法的字节码(iconst_1、iconst_2、iadd、ireturn)存储在方法区的方法元数据中。
解释执行启动:执行引擎调用main方法,栈帧管理器为main方法创建栈帧并推入虚拟机栈;解释器从方法区读取main方法的字节码,逐行解释执行。
调用add方法:解释器执行到add(1,2)时,栈帧管理器为add方法创建新栈帧(包含局部变量表a=1、b=2,操作数栈),推入虚拟机栈;程序计数器记录add方法的字节码执行位置。
解释执行add方法:解释器读取add方法的字节码:
iconst_1/iconst_2:将 1、2 压入操作数栈;
iadd:从操作数栈弹出 1 和 2,执行加法运算,将结果 3 压回操作数栈;
ireturn:将结果 3 返回给main方法的栈帧,add方法的栈帧出栈。
热点检测与 JIT 编译:若add方法被频繁调用(达到热点阈值),热点检测器会标记其为 “热点代码”,并通知 JIT 编译器。
JIT 编译与缓存:JIT 编译器(C1/C2)从方法区读取add方法的字节码,进行深度优化(如方法内联),编译为 CPU 可直接执行的机器码,并存入内存的 “代码缓存” 中。
编译执行:后续再次调用add方法时,执行引擎不再调用解释器,而是直接从代码缓存中读取编译后的机器码执行,执行效率大幅提升。
程序结束:main方法执行完毕,栈帧出栈;执行引擎通知 JVM 回收资源,程序退出。
JIT 编译器的执行效率优势,核心来自对字节码的深度优化,重点有一下4种方式:
方法内联(Method Inlining):将被调用的小方法的字节码,直接嵌入到调用方的方法中,消除 “方法调用的栈帧创建 / 销毁开销”,同时为后续优化创造条件。
例子:
public static int add(int a, int b) { return a + b; }
public static void main(String[] args) {
int sum = add(1,2) + add(3,4);
}
优化后:
public static void main(String[] args) {
int sum = (1+2) + (3+4); // 直接消除add方法的调用开销
}
逃逸分析(Escape Analysis):分析对象的作用域,判断对象是否 “逃逸” 出方法 / 线程:
基于逃逸分析的结果,JIT 会进行后续优化(标量替换、栈上分配)。
标量替换(Scalar Replacement):将未逃逸的对象拆解为多个基本数据类型(标量),直接存储在虚拟机栈的局部变量表中,避免在堆中创建对象,减少 GC 开销。
例子:
class Point { int x; int y; }
public static void printPoint() {
Point p = new Point(); // 对象未逃逸(仅在方法内使用)
p.x = 1;
p.y = 2;
System.out.println(p.x + p.y);
}
标量替换后:
public static void printPoint() {
int x = 1; // 拆解为标量,存储在局部变量表
int y = 2;
System.out.println(x + y);
}
死代码消除(Dead Code Elimination):移除程序中永远不会执行的代码(如条件恒为 false 的分支、未使用的变量赋值),减少执行指令数。
例子:
public static int calculate(int a) {
int b = a + 1;
if (false) { // 条件恒为false,分支内是死代码
b = a * 2;
}
return b;
}
死代码消除后:
public static int calculate(int a) {
int b = a + 1;
return b;
}
垃圾回收器(Garbage Collector)是 JVM 的 “内存管家”,核心作用是自动识别并回收堆中不再被引用的 “垃圾对象” 内存,避免内存泄漏和OutOfMemoryError(OOM),同时尽可能降低对业务线程的暂停影响(STW,Stop-The-World)。
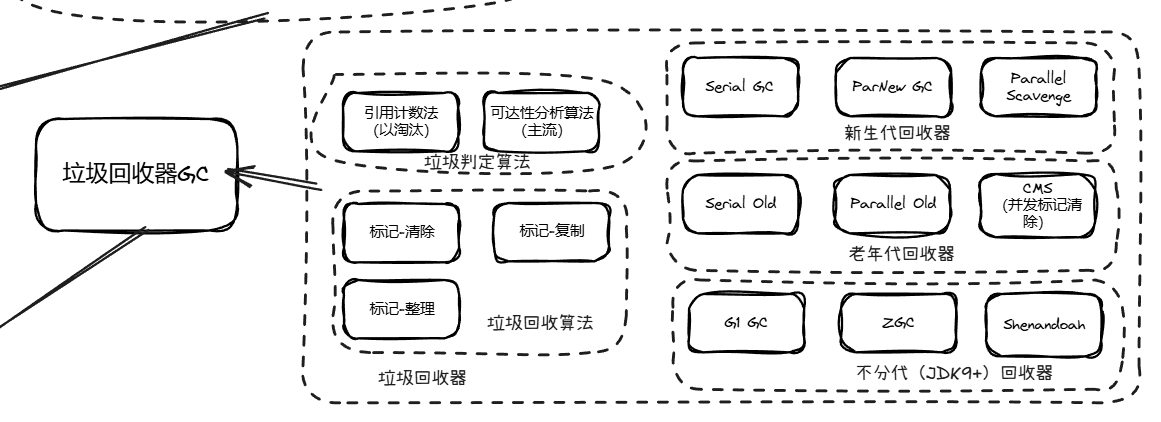
在讲具体回收器前,先明确 GC 的核心前提:
堆中无法被任何可达引用链指向的对象就是垃圾(比如局部变量执行完出栈后,指向的对象无其他引用)。
JVM 判断对象是否为垃圾的核心方式:
GC Roots(根节点,如虚拟机栈的局部变量、静态变量、本地方法栈的引用)为起点,遍历对象引用链,无法到达的对象即为垃圾。GC 主要回收堆内存(分代模型:新生代 + 老年代),方法区(元空间)也会回收但非核心:
新生代:存储新创建的对象,对象生命周期短,回收频率高(采用标记 - 复制算法,效率高);
新生代又分为:Eden 区(80%)+ Survivor0 区(10%)+ Survivor1 区(10%)。
老年代:存储从新生代存活下来的 “长寿对象”,回收频率低(采用标记 - 清除 / 标记 - 整理算法)。
所有垃圾回收器都基于以下 3 种核心算法实现,不同算法适配不同区域:
| 算法名称 | 核心步骤 | 优点 | 缺点 | 适用区域 |
|---|---|---|---|---|
| 标记 - 清除 | 1.标记所有垃圾对象;2. 直接清除垃圾对象 | 实现简单,无需移动对象 | 1.产生内存碎片;2. STW 时间长 | 老年代(CMS) |
| 标记 - 复制 | 1.标记存活对象;2. 复制到新内存区域;3. 清空原区域 | 无内存碎片,回收效率高 | 浪费 50% 内存(需预留空区域) | 新生代 |
| 标记 - 整理 | 1.标记存活对象;2. 移动存活对象到内存一端;3. 清除另一端 | 无内存碎片,不浪费内存 | 移动对象开销大,STW 时间较长 | 老年代 |
JVM 提供了多种垃圾回收器,按 “分代” 和 “适用场景” 可分为两类:分代回收器(适配新生代 + 老年代)、不分代回收器(G1/ZGC/Shenandoah)。
这类回收器分工明确:新生代回收器负责新生代 GC(YGC,Young GC),老年代回收器负责老年代 GC(Full GC)。
(1)新生代回收器
| 回收器名称 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Serial GC(串行) | 单线程执行 YGC,标记 - 复制算法,全程 STW | 占用 CPU 少,实现简单 | STW 时间长,效率低 | 单核 CPU、小内存(客户端程序) |
| ParNew GC | Serial 的多线程版本,标记 - 复制算法,全程 STW | 多线程提速 YGC | 占用多核 CPU | 配合 CMS 老年代回收器使用 |
| Parallel Scavenge | 多线程执行 YGC,标记 - 复制算法,关注吞吐量(可设置吞吐量目标) | 吞吐量高,适合批量处理 | STW 时间比 ParNew 略长 | 后台服务、批处理程序(JDK8 默认新生代回收器) |
(2)老年代回收器
| 回收器名称 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Serial Old | Serial 的老年代版本,单线程,标记 - 整理算法,全程 STW | 占用 CPU 少 | STW 时间极长 | 配合 Serial GC(客户端) |
| Parallel Old | Parallel Scavenge 的老年代版本,多线程,标记 - 整理算法,关注吞吐量 | 吞吐量高 | STW 时间较长 | 配合 Parallel Scavenge(JDK8 默认老年代回收器) |
| CMS(并发标记清除) | 多线程,标记 - 清除算法,关注低延迟,分 4 步: 1. 初始标记(STW,标记 GC Roots 直接引用) 2. 并发标记(不 STW,遍历引用链) 3. 重新标记(STW,修正并发标记的遗漏) 4. 并发清除(不 STW,清除垃圾) | STW 时间极短,响应性高 | 1.产生内存碎片;2. 占用 CPU 高;3. 有浮动垃圾(并发清除时产生的新垃圾) | 对延迟敏感的场景(如 Web 服务) |
这类回收器打破分代模型,将堆划分为多个大小相等的 Region(区域),兼顾吞吐量和低延迟,适合大内存场景(4G 以上)。
| 回收器名称 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| G1 GC(Garbage-First) | 1. 堆划分为多个 Region(新生代 / 老年代 Region 混合分布); 2. 优先回收垃圾多的 Region(Garbage-First); 3. 标记 - 复制 + 标记 - 整理结合,分 4 步:初始标记→并发标记→最终标记→筛选回收(STW) | 兼顾吞吐量和低延迟;2. 可设置最大 STW 时间(-XX:MaxGCPauseMillis);3. 无内存碎片 | STW 时间比 CMS 略长(但可控制) | 大内存(4G+)、混合场景(JDK9 + 默认) |
| ZGC | 基于 Region,采用 “染色指针” 技术,几乎全程并发执行,STW 时间 < 10ms | 极低延迟(STW<10ms),支持 TB 级内存 | 吞吐量略低于 G1 | 超大内存、超低延迟场景(如金融、电商核心服务) |
| Shenandoah | 与 ZGC 类似,全程并发,STW 时间 < 10ms,开源免费 | 极低延迟,适配更多平台 | 吞吐量略低 | 超低延迟、大内存场景 |
不同回收器不能随意组合,JVM 有固定搭配:

运行时数据区是 JVM 在执行 Java 程序时,专门用于存储运行时数据和执行上下文的内存区域,是 JVM 核心组成部分之一,它的设计直接决定了 JVM 的内存管理效率、线程安全特性,以及 GC 的回收范围。
核心作用:记录当前线程执行的字节码指令的行号指示器,相当于线程的 “执行书签”:
javap -v查看的字节码行号);native)时,计数器值为undefined(本地方法由 C/C++ 执行,JVM 无需跟踪)。核心特点
OutOfMemoryError(内存溢出),因为它的内存大小固定(仅存储一个地址 / 行号);核心作用:存储每个Java 方法执行的上下文,即栈帧(Stack Frame)。方法的调用过程对应栈帧的入栈,方法的执行完成对应栈帧的出栈。
int, boolean, char 等)、对象引用(reference 类型,不等同于对象本身,可能是指向对象起始地址的指针或句柄)和 returnAddress 类型(指向一条字节码指令的地址)。iadd 指令时,就从操作数栈弹出两个整数,相加后再压入。核心特点
-Xss(如-Xss1M)指定,超出则抛出 StackOverflowError(栈溢出);OutOfMemoryError;堆是 JVM 中内存最大、最重要的共享区域,也是 GC 的唯一核心回收目标(方法区回收为辅助)。
核心作用:存储所有对象实例和数组(几乎所有new出来的东西都存在这里),比如new User()、int[] arr = new int[10]。
核心特点
synchronized、volatile等机制保证;-Xms(堆初始大小)和-Xmx(堆最大大小)配置,如-Xms2G -Xmx4G;OutOfMemoryError: Java heap space;堆的分代模型
新生代:存储新创建的对象,对象生命周期短,回收频率高(每次 YGC 都回收),采用标记 - 复制算法(效率高);
老年代:存储从新生代存活下来的长寿对象,回收频率低(Full GC 时回收),采用标记 - 清除 / 标记 - 整理算法;
方法区是 JVM 规范中的概念,不同 JVM 实现有不同的落地方式:JDK7 及之前为永久代(PermGen),JDK8 及以后替换为元空间(Metaspace)。
核心作用:存储类的元数据信息,包括:
public/final等);static修饰的变量)、常量(final修饰的常量)。JDK7 vs JDK8:永久代 → 元空间(核心变化)
| 特性 | 永久代(JDK7 及之前) | 元空间(JDK8 及以后) |
|---|---|---|
| 内存位置 | 属于堆内存(堆的永久代分区) | 属于本地内存(JVM 进程外的系统内存) |
| 内存限制 | 受-XX:PermSize/-XX:MaxPermSize限制,默认大小小 | 受系统物理内存限制,默认无上限(可通过-XX:MetaspaceSize/-XX:MaxMetaspaceSize限制) |
| 异常类型 | 内存不足抛出OutOfMemoryError: PermGen space | 内存不足抛出OutOfMemoryError: Metaspace |
| GC 回收 | 随 Full GC 回收,效率低 | 独立的元空间 GC,触发条件更宽松,回收效率高 |
运行时常量池是方法区的重要组成部分,是从.class文件的常量池加载而来的运行时版本。
核心作用:存储编译期生成的常量和运行期动态生成的常量,包括:
"hello")、基本类型常量(如123);String.intern()动态加入的字符串常量(运行时生成)。核心特点
String.intern());OutOfMemoryError(永久代 / 元空间 / 堆,取决于 JDK 版本)。在最后,附上整体完整的图